

快科技3月8日消息,今年除夕当天阿里发布了千问Qwen 3.5系列大模型,之前发布的是高端大尺寸系列,前几天发了四个小尺寸模型Qwen3.5-0.8B/2B/4B/9B。
玩过Qwen模型的网友都知道,小尺寸的AI模型是它们的灵魂,本地部署的吸引力是无法抵挡的,而Qwen 3.5系列米乐M6 米乐平台这次不仅小,性能也够强,其中9B版性能就媲美gpt-oss-120B。
实际表现可能还要出乎大家的意料,N8 Programs日前实际测试了一下验证官方所说的4B版跟GPT-4o一样好的说法。
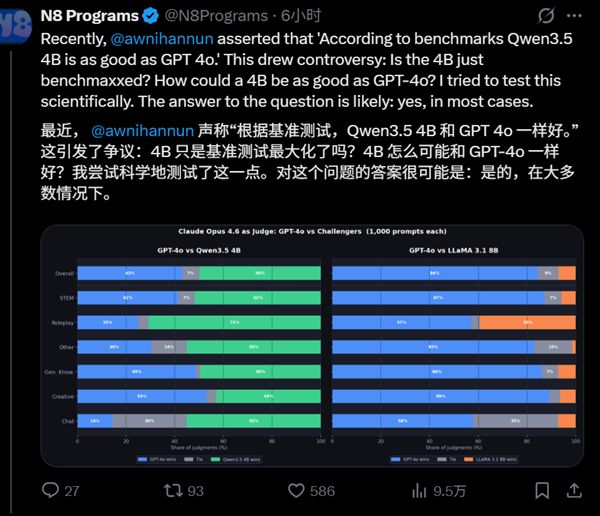
先说结论,大多数情况下还是这样,Qwen 3.5-4B在测试中跑赢了GPT-4o这样的主力大模型。
他使用了WildChat数据集里的1000个随机问题,让两个大模型都做答,然后用目前最强的大模型Opus 4.6做判断,最终Qwen 3.5-4B在1000个问答中赢了499个,输了431个,平局70个,可见千问官方还是很实在的宣传。
要知道Qwen 3.5-4B就是个40亿参数量的小模型,而GPT-4o还是很多人的主力模型,其参数量高达2000亿(具体数字OpenAI官方没提过,微软论文证实过),Qwen 3.5-4B只用了后者2%的参数量就做到了性能略强。
Qwen 3.5这几个小模型当然不可能什么都超过目前的顶流模型,但本地部署的线GB显存,然后再量化优化下,网上有很多教程,感兴趣的网友可以去玩玩。
场景:非常适合移动设备、IoT 边缘设备部署,以及低延时的实时交互场景。
场景:适合需要较高智力水平但受限显存资源的服务器端部署,是性价比极高的通用模型选择。
多地宣布生物地理不再计入中考总分:官方回应突出语数英核心科目权重、弱化分数
宇树王兴兴:字节跳动Seedance 2.0 视频生成软件 我觉得是全球目前最好的
最强鸿蒙二合一平板 全新华为MatePad Edge来了 搭载麒麟X90芯片、微泵液冷
国家安全部通报无人机黑飞案例 发烧友破解限飞至8000米高空危及民航安全
Mate 80系列同款星环设计!华为畅享90 Pro Max全配色外观公布